On February 10 2017 the 27th edition of the Computational Linguistics in the Netherlands conference will be held in Leuven. As part of this conference they organise a “shared task”. This year, this task is a competition in “translating” the bible from old Dutch to new Dutch. As a small experiment I tried to transform each word from old Dutch to new Dutch using a neural network. Below are my results (adapted from an IPython notebook that can be found here: https://github.com/rmeertens/Old-dutch-to-new-dutch-tensorflow).
In 1637 the first translation of the bible from the original Hebrew, Aramaic, and Greek languages to Dutch was published (https://en.wikipedia.org/wiki/Statenvertaling). As the Dutch language changed over the years (under influence of Spain and other countries that conquered us) the bible was translated to newer and newer Dutch.
The difference can be spotted easily between the 1637 and 1888 version:
1637: De Aerde nu was woest ende ledich, ende duysternisse was op den afgront: ende de Geest Godts sweefde op de Wateren.
1888: De aarde nu was woest en ledig, en duisternis was op den afgrond; en de Geest Gods zweefde op de wateren.
If you are Dutch you can probably read the 1637 version, although you will need some time to find the right words. The letters ae (aerde) changed to aa (aarde), ch (ledich) changed to g (ledig) and some words ending in t (afgront) now end with the d (afgrond). Even the word Godt changed to God in just 250 years.
Apart from the spelling some words completely changed. For example:
1637: Ende sy waren beyde naeckt, Adam ende sijn wijf:
1888: En zij waren beiden naakt, Adam en zijn vrouw;
Nowadays calling a woman a “wijf” would be an insult..
As it takes historians a long time to read old texts in their original form, we would like to make them a bit more readable. What is interesting is that the Google search bar understands what you want to say with their autocorrect:
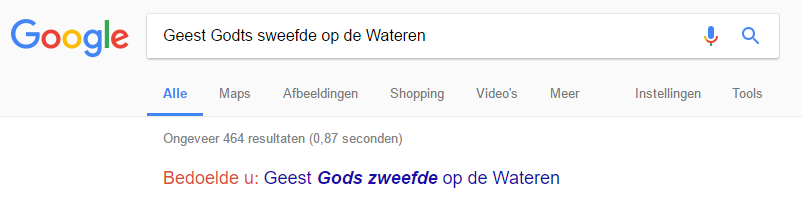
How you can implement Google’s autocorrect was written down by Peter Norvig in this excellent post: http://norvig.com/spell-correct.html .
Using the “Autocorrect function” you can build a dictionary of words from old Dutch to new Dutch (if you would like to see this in a blogpost, please contact me). What I wanted to do was train a dictionary on a small number of words, and use neural networks to generalise the conversion of old Dutch to new Dutch.
Preparation
I automatically created a dictionary with the old Dutch and new Dutch version of 20.852 words. If this is enough for deep neural networks is something we will find out at the end of this project. Adding more data is difficult as the only aligned old-new data I have is the bible with 37.235 lines of text.
The network
My plan is to use a recurrent neural network (https://en.wikipedia.org/wiki/Recurrent_neural_network) encoder that reads all characters, and a recurrent neural network decoder that generates characters. The data should be preprocessed with this idea in mind… This means setting a max length to the words that we want to transform, and some other tricks I will discuss later.
import random
from keras.preprocessing import sequence
import tensorflow as tf
import numpy as np
Xdata = []
Ydata = []
MAX_LENGTH_WORD = 10
feature_dict= dict()
feature_list = list()
PADDING_CHARACTER = '~'
feature_dict[PADDING_CHARACTER]=0
feature_list.append(PADDING_CHARACTER)
max_features = 1
def get_vector_from_string(input_s):
global max_features
vector_x = []
for i in input_s:
if i not in feature_dict:
feature_dict[i]=max_features
feature_list.append(i)
max_features += 1
vector_x.append(feature_dict[i])
return vector_x
def add_to_data(input_s,output_s):
if len(input_s) < MAX_LENGTH_WORD and len(output_s) < MAX_LENGTH_WORD:
vector_x = get_vector_from_string(input_s)
vector_y = get_vector_from_string(output_s)
Xdata.append(vector_x)
Ydata.append(vector_y)
def print_vector(vector,end_token='\n'):
print(''.join([feature_list[i] for i in vector]),end=end_token)
with open("dictionary_old_new_dutch.csv") as in_file:
for line in in_file:
in_s,out_s = line.strip().split(",")
add_to_data(in_s,out_s)
for i in range(10):
print_vector(Xdata[i],end_token='')
print(' -> ', end='')
print_vector(Ydata[i])
Data preprocessing
As mentioned above I would like to use a sequence to sequence approach. Important for this approach is having a certain length of words. Words that are longer than that length have been discarded in de data-reading step above. Now we will add paddings to the words that are not long enough.
Another important step is creating a train and a test set. We only show the network examples from the train set. At the end I will manually evaluate some of the examples in the testset and discuss what the network learned. During training we train in batches with a small amount of data. With a random data splitter we get a different trainset every run.
before_padding = Xdata[0]
Xdata = sequence.pad_sequences(Xdata, maxlen=MAX_LENGTH_WORD)
Ydata = sequence.pad_sequences(Ydata, maxlen=MAX_LENGTH_WORD)
after_padding = Xdata[0]
print_vector(before_padding,end_token='')
print(" -> after padding: ", end='')
print_vector(after_padding)
class DataSplitter:
def __init__(self,percentage):
self.percentage = percentage
def split_data(self,data):
splitpoint = int(len(data)*self.percentage)
return data[:splitpoint], data[splitpoint:]
splitter = DataSplitter(0.8)
Xdata,Xtest = splitter.split_data(Xdata)
Ydata,Ytest = splitter.split_data(Ydata)
def get_random_reversed_dataset(Xdata,Ydata,batch_size):
newX = []
newY = []
for _ in range(batch_size):
index_taken = random.randint(0,len(Xdata)-1)
newX.append(Xdata[index_taken])
newY.append(Ydata[index_taken][::-1])
return newX,newY
batch_size = 64
memory_dim = 256
embedding_dim = 32
enc_input = [tf.placeholder(tf.int32, shape=(None,)) for i in range(MAX_LENGTH_WORD)]
dec_output = [tf.placeholder(tf.int32, shape=(None,)) for t in range(MAX_LENGTH_WORD)]
weights = [tf.ones_like(labels_t, dtype=tf.float32) for labels_t in enc_input]
dec_inp = ([tf.zeros_like(enc_input[0], dtype=np.int32)]+[dec_output[t] for t in range(MAX_LENGTH_WORD-1)])
empty_dec_inp = ([tf.zeros_like(enc_input[0], dtype=np.int32,name="empty_dec_input") for t in range(MAX_LENGTH_WORD)])
cell = tf.nn.rnn_cell.GRUCell(memory_dim)
# Create a train version of encoder-decoder, and a test version which does not feed the previous input
with tf.variable_scope("decoder1") as scope:
outputs, _ = tf.nn.seq2seq.embedding_attention_seq2seq(enc_input,dec_inp,
cell,max_features,max_features,
embedding_dim, feed_previous=False)
with tf.variable_scope("decoder1",reuse=True) as scope:
runtime_outputs, _ = tf.nn.seq2seq.embedding_attention_seq2seq(enc_input,empty_dec_inp,
cell,max_features,max_features,
embedding_dim,feed_previous=True)
loss = tf.nn.seq2seq.sequence_loss(outputs, dec_output, weights, max_features)
optimizer = tf.train.AdamOptimizer()
train_op = optimizer.minimize(loss)
# Init everything
sess = tf.InteractiveSession()
sess.run(tf.initialize_all_variables())
for index_now in range(1002):
Xin,Yin = get_random_reversed_dataset(Xdata,Ydata,batch_size)
Xin = np.array(Xin).T
Yin = np.array(Yin).T
feed_dict = {enc_input[t]: Xin[t] for t in range(MAX_LENGTH_WORD)}
feed_dict.update({dec_output[t]: Yin[t] for t in range(MAX_LENGTH_WORD)})
_, l = sess.run([train_op,loss], feed_dict)
if index_now%100==1:
print(l)
Train analysis
Looks like we are learning something! The loss is going down the first 500 steps. After that the loss is not reduced a lot anymore. This is possible because natural language is difficult, and rules of old Dutch to new Dutch are not always consistent. Without an additional dictionary to verify the solutions the network made I think it will be difficult to train a perfect network.
Now it’s test time! Let’s input some words the network has not seen before and see what rules it learned.
def get_reversed_max_string_logits(logits):
string_logits = logits[::-1]
concatenated_string = ""
for logit in string_logits:
val_here = np.argmax(logit)
concatenated_string += feature_list[val_here]
return concatenated_string
def print_out(out):
out = list(zip(*out))
out = out[:10] # only show the first 10 samples
for index,string_logits in enumerate(out):
print("input: ",end='')
print_vector(Xin[index])
print("expected: ",end='')
expected= Yin[index][::-1]
print_vector(expected)
output = get_reversed_max_string_logits(string_logits)
print("output: " + output)
print("==============")
# Now run a small test to see what our network does with words
RANDOM_TESTSIZE = 5
Xin,Yin = get_random_reversed_dataset(Xtest,Ytest,RANDOM_TESTSIZE)
Xin_transposed = np.array(Xin).T
Yin_transposed = np.array(Yin).T
feed_dict = {enc_input[t]: Xin_transposed[t] for t in range(MAX_LENGTH_WORD)}
out = sess.run(runtime_outputs, feed_dict)
print_out(out)
def translate_single_word(word):
Xin = [get_vector_from_string(word)]
Xin = sequence.pad_sequences(Xin, maxlen=MAX_LENGTH_WORD)
Xin_transposed = np.array(Xin).T
feed_dict = {enc_input[t]: Xin_transposed[t] for t in range(MAX_LENGTH_WORD)}
out = sess.run(runtime_outputs, feed_dict)
return get_reversed_max_string_logits(out)
interesting_words = ["aerde","duyster", "salfde", "ontstondt", "tusschen","wacker","voorraet","gevreeset","cleopatra"]
for word in interesting_words:
print(word + " becomes: " + translate_single_word(word).replace("~",""))
Test analysis
Looks like our network learned simple rules such as (ae) -> (aa), (uy) -> (ui), (s) -> (z) if at the start of a word. There are also difficult cases, such as tusschen (tussen). Some words (voorraet) are difficult, as in modern Dutch the last t changed to a d (but this is not a hard rule, you simply have to learn it).
Translating “cleopatra” is an interesting case. As it is a name, you don’t want to change it… The network can’t know this, and simply renames her to “kleopatra”
Conclusion
Using a neural network to go from old Dutch to new Dutch has been mildly succesful. Some words are “translated” correctly, while others unfortunately are mistranslated. It has been a fun experiment, and it is still interesting to see what rules were “easy” to learn, and what rules are difficult to learn.
If you want to toy around with this model, or have any questions, please let me know!





Facebook Comments (
G+ Comments ()